
What is Crawl Depth?
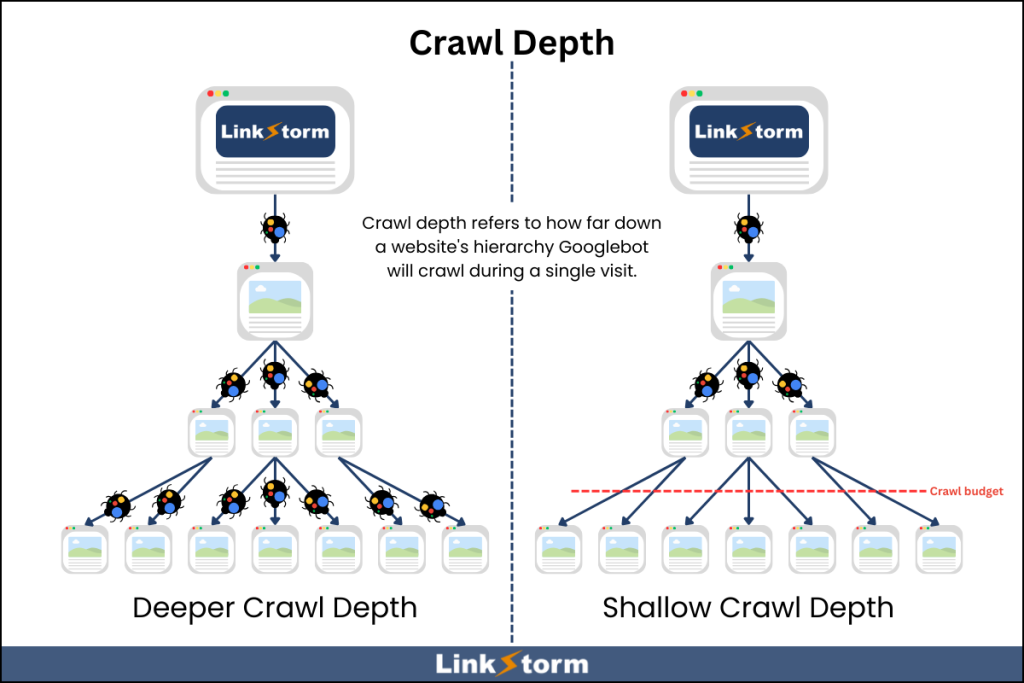
Crawl depth refers to how far down a website’s hierarchy Googlebot will crawl during a single visit. A website with a higher crawl depth means that Google can crawl and index more pages directly from the homepage. On the other hand, websites with shallow crawl depth will have fewer pages crawled and indexed.
Before any web page makes it into Google’s SERPs, search engine crawlers will have to follow a three-step process:
- Crawling: Web crawlers discover new websites by following links from indexed pages or exploring sitemaps.
- Indexing: Relevant and valuable content are added to Google’s database, allowing them to appear in search engine results.
- Ranking: Google’s algorithm evaluates indexed pages based on various factors, arranging them according to relevance to the search query.
Crawling is arguably the most crucial of the three steps. Unless search engine bots can crawl or reach a specific page, its visibility on search results will be severely limited. This also impacts how much value your business can get from your content.
However, the search engine bot has limited time and resources. Google allocates a specific crawl budget on a website. Site owners must ensure the website’s important pages can be crawled within the allotted crawl budget.
This is where the concept of crawl depth comes in. Let’s explore further.
Relationship Between Crawl Depth and Crawl Budget
According to Google, crawl budget is to the amount of time and resources the search engine allocates to crawl a website. It is dynamic value—sometimes the budget is more, sometimes less, depending on a lot of factors.
Crawling the web is not a perpetual process, but has intervals between each crawling activity. Google sets a dedicated crawl budget for each session based on two factors: crawl capacity limit and crawl demand.
Google will crawl as many pages as possible as long as it doesn’t overwhelm your servers. This is called the crawl capacity limit. The crawling process continues while your website responds quickly but will taper down once it slows down or encounters server errors. Besides your server, your crawl rate is also limited by how much of Google’s resources it can devote to crawling your website.
The nature of your website also impacts its crawl budget allotment. News websites, popular websites, or sites that are updated frequently will usually receive more crawl budget from Google than less popular, low-quality websites. This is called crawl demand.
Check out how Martin Splitt explained crawl budget and the factors affecting it [timestamp at 1:12 to 2:44]:
A website’s crawl budget is the combination of its crawl capacity limit and crawl demand. And with a larger allocated crawl budget, Google can spend more time exploring your website.
In other words, the higher the crawl budget, the deeper the crawl depth.
Crawl Depth vs. Click Depth: What is the Difference?
Many use crawl depth and click depth interchangeably, but while related, these two are two distinct concepts.
Click depth, or page depth, refers to the easiest or most intuitive number of clicks required to reach a particular page from the homepage. For instance, if it takes three clicks from your homepage, then that page has a click depth of 3.
Meanwhile, crawl depth refers to the level at which Googlebot will access down a website structure.
At face value, click depth and crawl depth might look similar. In an average website, the homepage has a click and crawl depth of 0. And this value increases the farther a page is from the homepage.
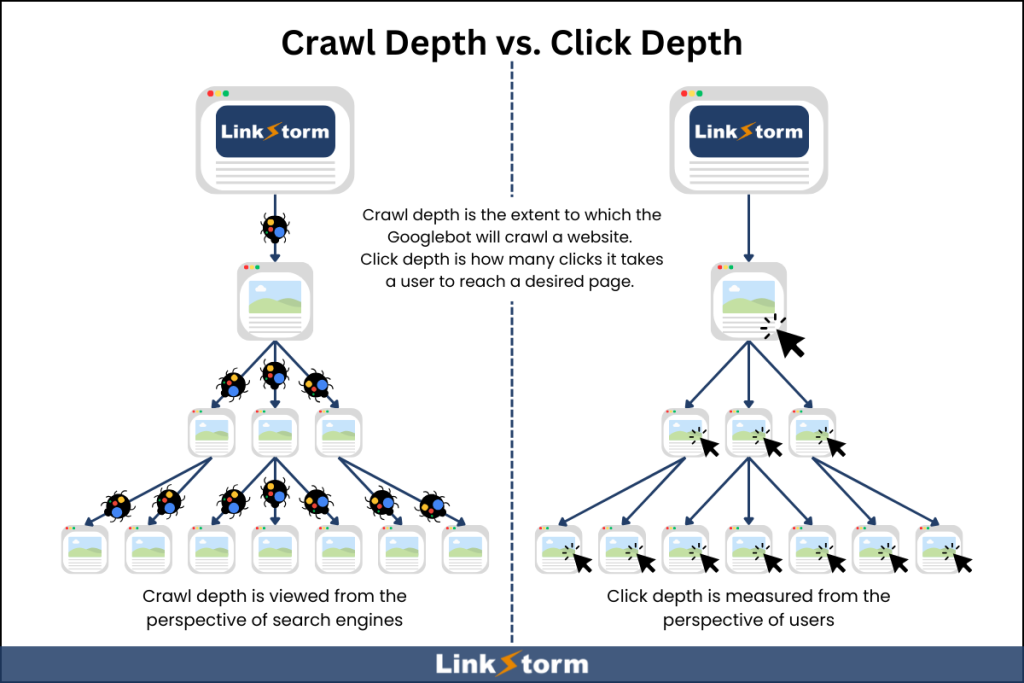
One difference between the two is the perspective which you’re viewing it from: Click depth is from the user’s perspective, while crawl depth is from Googlebot’s viewpoint.
Another difference is the page’s positioning within the site’s internal linking structure. For instance, a specific product page may be linked in the footer (click depth = 1), but physically found under /category/subcategory/product (crawl depth = 3).
Click depth is straightforward, measuring literally how many clicks it takes. But search engines may calculate crawl depth differently if they prioritize the page’s hierarchy in the URL structure or sitemap.
Why is Crawl Depth Important for SEO?
Crawl depth is important because it determines the extent to which Google spends time exploring your pages on your site. Web pages at the far ends of your architecture might not be visited if your crawl budget limit has been reached. This highlights the significance of optimizing crawl depth and ensuring relevant pages are easily accessible to web crawlers.
Google also assigns a different value or relative importance to a page depending on its crawl depth. The homepage is generally the “strongest” page on the website hierarchy. And Google treats pages closest to the homepage as more important than pages buried deep.
Here’s what John Mueller has to say about it [timestamp at 32:23 to 33:07]:
This emphasizes the need to reduce crawl depth ensuring that important pages are as close to the homepage as possible. On that note, let’s look at actionable tips for optimizing a site’s crawl depth for better visibility and ranking:
How to Increase Crawl Efficiency in Your Website?
1. Optimize your internal linking strategy
Internal links directly benefit users and search engine crawlers by giving them access to linked pages. Implement strategic internal linking to ensure no pages are isolated and all pages are discoverable by Googlebot.
If you use a topic cluster strategy, link all relevant cluster content to the pillar page and vice versa. Moreover, look for opportunities to interlink cluster content among themselves. This ensures there are no dead ends in a search engine’s crawling journey, and they can explore for as long as their crawl budget allows.
Make sure your important pages, such as the product and services page and other money pages, are linked directly to your homepage. Then, arrange each page’s crawl depth according to their relative importance.
An internal linking tool, like LinkStorm, automates the linking process by finding relevant internal linking opportunities sitewide.
It also shows the click depth of the source and target pages. You improve crawl efficiency by linking low-click depth to high-click depth pages on your website.
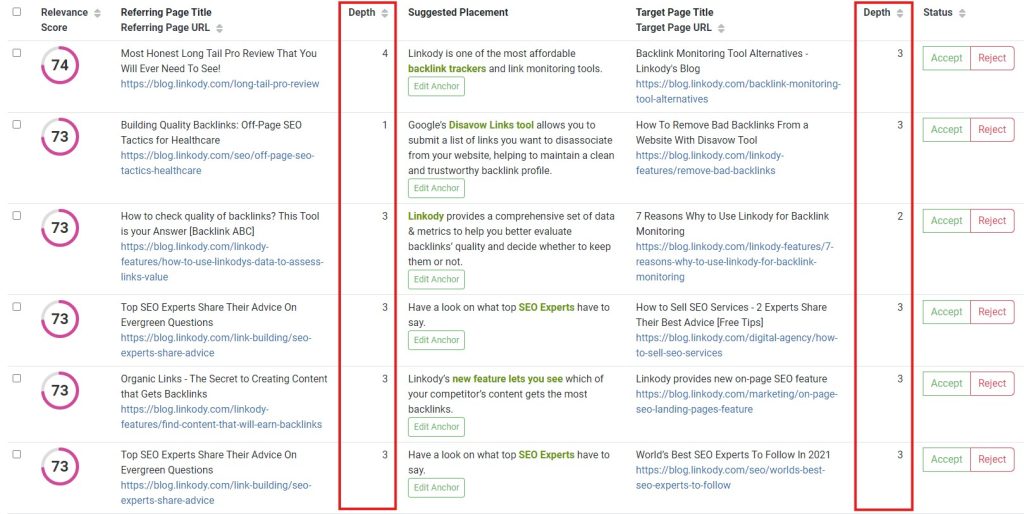
This allows search engines to crawl and index quicker without using up too much crawl budget.
2. Resolve broken pages
Broken internal links serve as obstructions in a search engine’s crawling journey. Even with a high crawl budget, broken links prevent crawlers from exploring the website further.
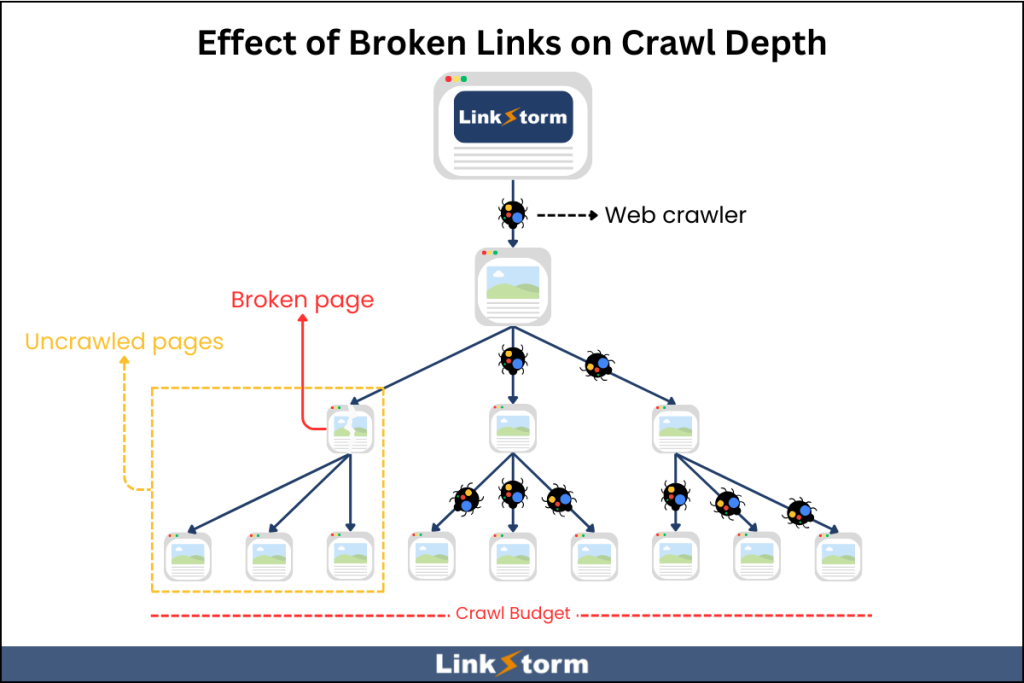
An internal link audit lets you identify and resolve broken links on your website. While auditing can be done manually, an internal linking tool can automatically find sitewide issues.
Using LinkStorm, click the Issues tab on the left-side panel.
This takes you to a page revealing issues, such as broken links, redirects, and nofollows.
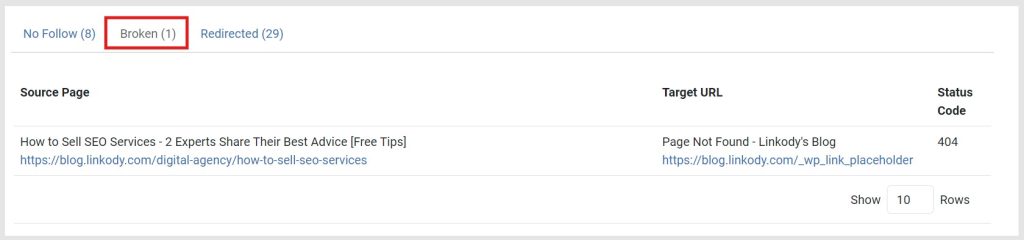
Use the provided information to update the broken links with the correct URL.
3. Monitor redirects
Mismanaged URL redirects can result to redirect loops or redirect chains.
A redirect chain is a series of redirects that causes web crawlers to go through various links before reaching the final URL. For example, crawling a link goes to URL A, which redirects to URL B that then redirects to URL C, and so on.
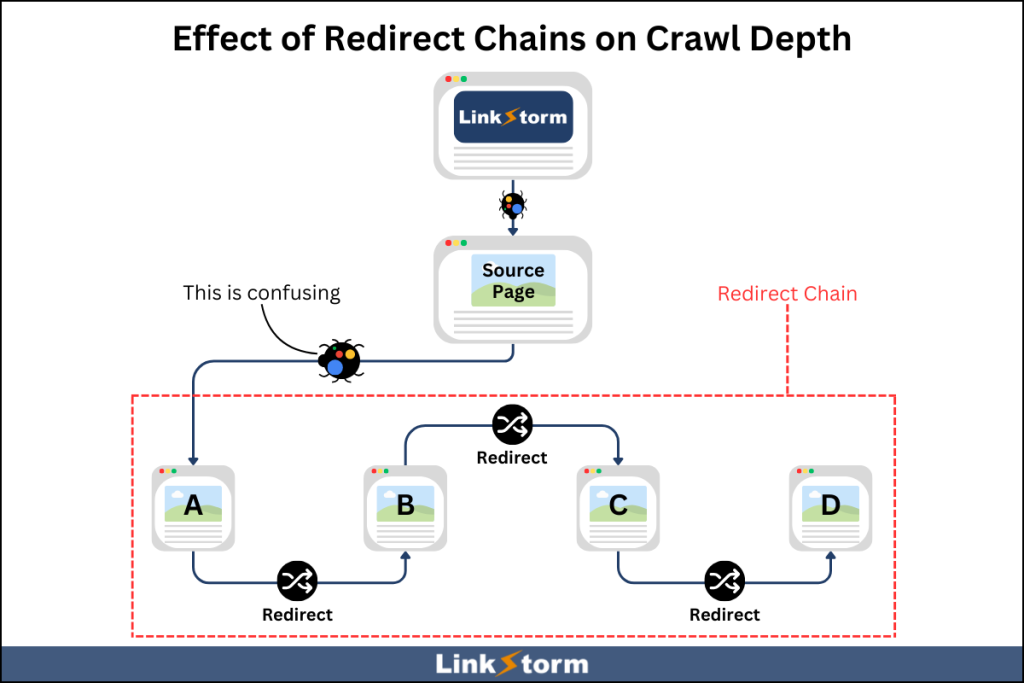
This chain results in slow loading times, affecting user experience. Search engines might also not follow a redirect chain, preventing them from crawling the pages.
A redirect loop occurs when a page redirects to itself or other pages in a circular fashion. This endless cycle prevents web crawlers from reaching the targeted page. For instance, clicking a link goes to URL A, which redirects to URL B, which then redirects back to URL A, then repeats.
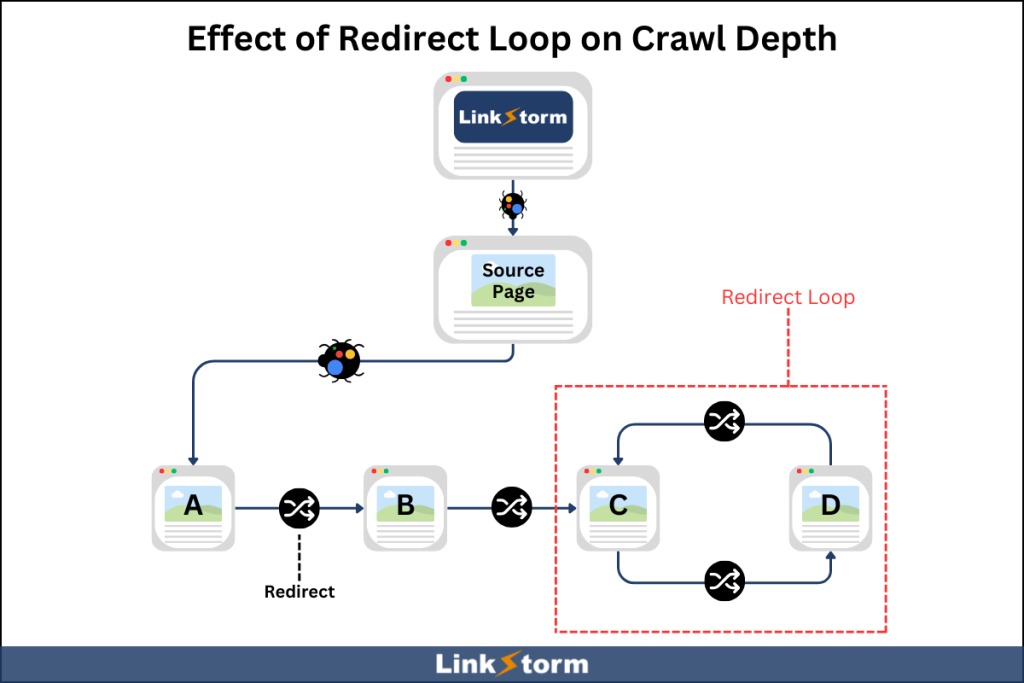
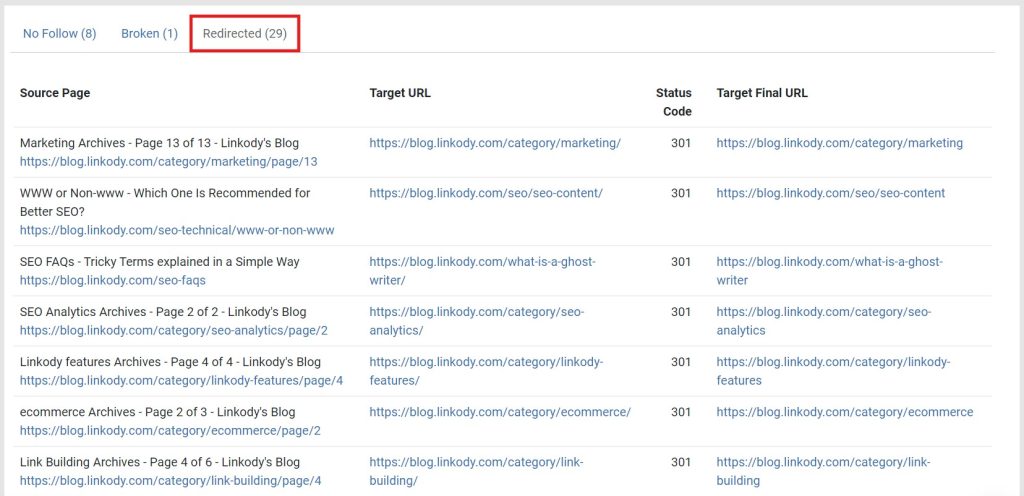
LinkStorm identifies redirects on a website via its Issues tab. To find redirects on your site, select the “redirect” option. This should show all redirects found on your website. Check whether these redirects create a loop or chain.
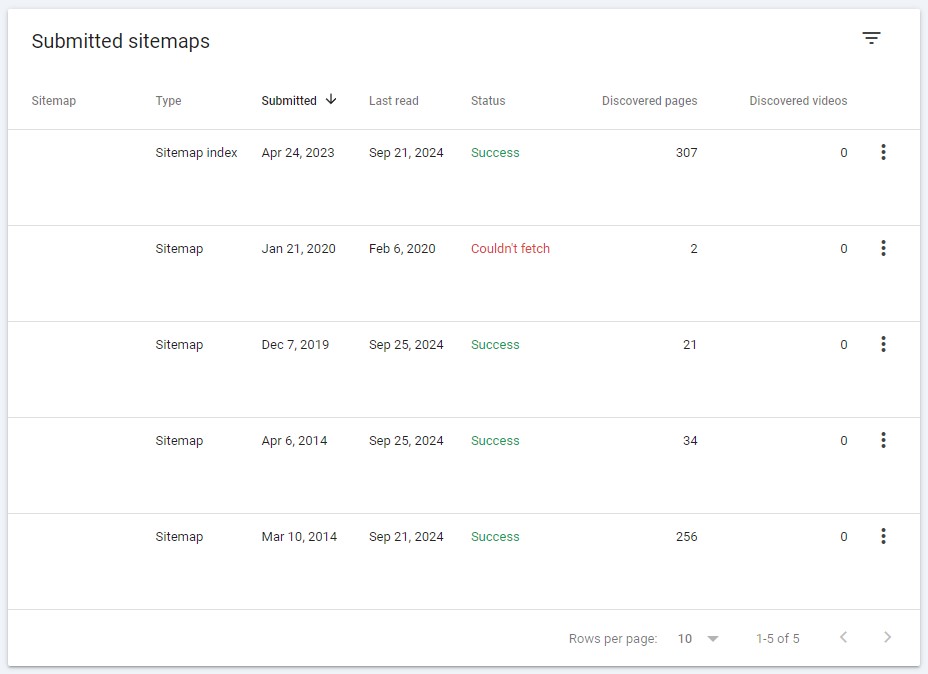
4. Submit an XML sitemap to Google
An XML sitemap lists all pages throughout your website. If you haven’t already, submitting an XML sitemap helps Google discover your content more efficiently.
Most content management systems, like WordPress, have built-in sitemaps submitted automatically to Google Search Console. However, if you don’t have one, you can visit a free XML sitemap generator and submit it manually to GSC to optimize crawl depth effectively.
5. Ensure your website has no duplicate content
Duplicate content may confuse search engines about which is more important between the two.
If you have duplicate content, add a canonical tag on the page you want Google to prioritize for indexing and ranking.
Another solution is merging those duplicates into one page, consolidating all essential information from both content. Add a 301 redirect from the duplicate to funnel all traffic to the canonical page.
Doing this prevents web crawlers from spending their crawl budget on both copies. Instead, the budget can be dedicated to other pages.
Need Help Boosting Your Crawl Efficiency?
Improving crawl efficiency means search engine crawlers can effectively navigate and index your website’s content. Internal links are at the core of a website with high crawl efficiency.
LinkStorm automates the internal linking process, helping you maintain a well-connected website and ensuring no page is overlooked by web crawlers.
Interested?
Check out LinkStorm’s pricing page to see which plan best suits your website’s needs.
Happy linking!
Leave a Reply